
Imagine Video Generator
Loading...
Imagine Video Generator
Loading...

The AI video generation landscape has exploded in 2026, with two powerhouse models dominating conversations: Grok Imagine and Seedance 2.0. We compare their features, performance, speed, and cost to help you decide which tool fits your creative workflow.
The AI video generation landscape has exploded in 2026, with two powerhouse models dominating conversations among creators, marketers, and production teams: Grok Imagine from xAI and Seedance 2.0 from ByteDance. Both promise to revolutionize how we create video content, but they take dramatically different approaches to solving the same problem.
After extensive research into real-world performance benchmarks, user feedback, and technical specifications, we've compiled this comprehensive comparison to help you understand which model truly delivers on its promises—and more importantly, which one fits your specific creative workflow.

Before diving into the head-to-head comparison, it's crucial to understand where we stand. AI video generation has transformed from producing blurry, seconds-long clips with obvious artifacts into creating cinema-quality footage with realistic physics, coherent motion, and synchronized audio. The technology has matured to the point where professional productions are integrating AI-generated sequences into commercial workflows.
The key differentiators in 2026 are no longer just about whether a model can generate video—they all can. The real questions are: How well does it follow complex instructions? Can it maintain visual consistency across longer sequences? Does it generate native audio that actually syncs with the action? And perhaps most critically for businesses: What's the cost-per-second, and how fast can you iterate?

Join the Grok Video community
Subscribe for the latest Grok Video Generator news and updates
Grok Imagine represents xAI's ambitious entry into video generation, built on the same foundation as their image generation capabilities. Released in January 2026, this model has quickly gained traction for one compelling reason: it prioritizes speed and cost-effectiveness without sacrificing creative control.
Grok Imagine operates on a straightforward value proposition. The model generates videos from 6 to 15 seconds in duration, with native audio-video synchronization powered by what xAI calls the Aurora Engine. Unlike earlier AI video tools that generated silent clips requiring separate audio processing, Grok Imagine creates background music, sound effects, and even dialogue automatically synchronized with visual events.
The model supports five distinct workflows:
Text-to-video: Transform written prompts into video sequences
Image-to-video: Animate static images with realistic motion
Video-to-video: Edit existing footage using text instructions
Image editing: Modify images through natural language
Text-to-image: Generate static visuals as starting points
What sets Grok Imagine apart is its instruction-following capability. The model excels at understanding complex creative direction—restyle scenes, add or remove objects, control motion dynamics, and adjust camera behavior through natural language prompts. This level of control has proven particularly valuable for rapid iteration and creative exploration.
| Specification | Grok Imagine |
|---|---|
| Resolution | 720p (capped) |
| Duration | 6-15 seconds |
| Aspect Ratios | 16:9, 9:16, 1:1, 4:3, 3:4 |
| Audio | Native audio-video sync |
| Pricing | $0.05 per second |
| API Access | Yes, via xAI API |
| Generation Speed | Fast (P50 latency optimized) |
The 720p resolution cap represents Grok Imagine's most significant technical limitation. For professional productions requiring 1080p or higher output, this constraint immediately disqualifies the model from certain use cases. However, for social media content, rapid prototyping, and creative exploration, the resolution proves sufficient for most applications.
At $0.05 per second of generated video, Grok Imagine positions itself as one of the most cost-effective options in the market. A 10-second video costs just $0.50—dramatically lower than traditional video production and competitive with other AI models. This pricing structure makes high-volume generation economically viable for businesses testing multiple creative variations.
The model is accessible through two primary channels:
X Premium Subscriptions: Basic tier at $8/month with usage limits, Premium+ with fewer restrictions, and SuperGrok with unlimited access
API Access: Direct integration for developers and businesses at $0.05/second with no cold starts, ensuring production reliability
The absence of cold starts represents a significant operational advantage. Many competing platforms experience timeout issues on first-generation requests while servers spin up. Grok Imagine maintains ready infrastructure, delivering consistent performance from the first API call.
User feedback and benchmark testing reveal Grok Imagine's strengths and limitations with clarity. The model prioritizes speed and stylistic flexibility over photorealism. When tested against competitors like Sora 2 and Veo 3, Grok Imagine consistently generates results faster but produces output that leans toward stylized, artistic interpretations rather than cinema-quality realism.
Independent testing by Tom's Guide using seven challenging prompts found that Grok Imagine "leans into personality and flair, often producing videos that feel stylized and bold, even when they miss some realism." The model excels at creative, fantastical scenes but struggles with photorealistic requirements. For example, when prompted to generate a fox in an enchanted forest, Grok Imagine produced a storybook-like aesthetic with glowing colors and painterly textures—mesmerizing but not realistic.
The model shows noticeable progress in facial expressions and emotional authenticity—historically weak points for AI video generation. Where earlier models produced stiff, disconnected faces creating an uncanny valley effect, Grok Imagine delivers more natural emotional responses synchronized with scene context.
However, limitations persist. Users report inconsistent audio quality in some generations, and the model hasn't achieved the photorealistic standards set by Google's Veo 3 or OpenAI's Sora 2. For creators prioritizing speed, experimentation, and stylistic content over documentary-level realism, these trade-offs prove acceptable.
ByteDance's Seedance 2.0 represents a fundamentally different philosophy. Rather than optimizing for speed and accessibility, Seedance 2.0 targets professional-grade output suitable for commercial applications, social media campaigns, and even cinematic storytelling. Released in February 2026, the model builds on ByteDance's extensive video technology expertise—the same infrastructure powering TikTok's sophisticated recommendation and processing systems.
Seedance 2.0's defining innovation is autonomous multi-shot storytelling. Unlike earlier AI video models that generated single continuous shots, Seedance 2.0 demonstrates "director-level" thinking—it grasps complex narrative logic and autonomously orchestrates cinematic techniques including push-in, pull-out, pan, and tilt camera movements. Videos are no longer simple static-image translations but possess genuine cinematic narrative structure.
This capability addresses one of the most persistent frustrations in AI video generation: the "gacha loop" where creators repeatedly generate dozens of outputs hoping to obtain a few seconds of stable, consistent footage. Seedance 2.0's core breakthrough transforms "technical showmanship" into "deliverable storytelling." The model automatically generates coherent multi-shot sequences with consistent characters, style, and atmosphere throughout—no manual stitching required.
Like Grok Imagine, Seedance 2.0 generates audio and video simultaneously rather than as separate processes requiring post-production alignment. However, Seedance 2.0 employs a dual-branch diffusion transformer architecture—one transformer dedicated to video, another to audio—enabling joint generation where audio and visual information inform each other during creation.
This approach ensures tight synchronization and enables the model to create audio that responds to visual events (footsteps matching character movement) and visuals that respond to audio cues (lip movements matching speech). The result eliminates the "drift" problem plaguing earlier models where sound effects didn't quite match on-screen action.
| Specification | Seedance 2.0 |
|---|---|
| Resolution | 1080p-2K (true broadcast quality) |
| Duration | 5-60 seconds |
| Aspect Ratios | Multiple (optimized for various platforms) |
| Audio | Dual-branch native sync |
| Multimodal Input | Text, image, audio, video combinations |
| API Access | Yes, via ByteDance Dreamina |
| Generation Speed | Moderate (quality-optimized) |
The resolution advantage is substantial. Seedance 2.0 generates videos at true 1080p resolution with options extending to 2K, delivering broadcast-quality output meeting professional standards. The visual fidelity represents a significant improvement over earlier AI video models, with crisp details, accurate color reproduction, and minimal artifacts.
Seedance 2.0 accepts multimodal inputs—text, images, audio, and video can be combined in various configurations to guide generation. This flexibility enables sophisticated creative workflows. For example, you can provide a reference image for visual style, an audio track for mood and pacing, and text instructions for specific narrative elements. The model synthesizes these inputs into coherent output respecting all constraints.
Seedance 2.0 looks especially strong in early testing on visual consistency, which is one of the hardest failure points in AI video generation.
Facial distortion during subject motion and sharp-blurry hybrid artifacts in backgrounds remain common issues across competing models. Seedance 2.0 does a better job maintaining facial integrity and background consistency throughout motion sequences, with particular strength in handling complex scenes.
Independent reviewers note that Seedance 2.0 excels at motion realism, narrative continuity, and cinematic camera behavior—the three persistent issues making AI-generated content unusable for professional workflows. The model's ability to maintain temporal coherence across multi-second clips sets it apart from competitors.
Seedance 2.0's pricing structure differs from Grok Imagine's straightforward per-second model. For a 5-second 1080p video, costs run under $1, with transparent tiering at $1.8–$2.5 per million tokens depending on whether you use the Lite or Pro model. The pricing remains competitive while targeting professional applications where output quality justifies higher investment.
The model is optimized for high concurrency, enabling developers and teams to generate large volumes of videos simultaneously without performance degradation. This architectural decision reflects ByteDance's enterprise focus—supporting production environments where multiple team members generate content in parallel.
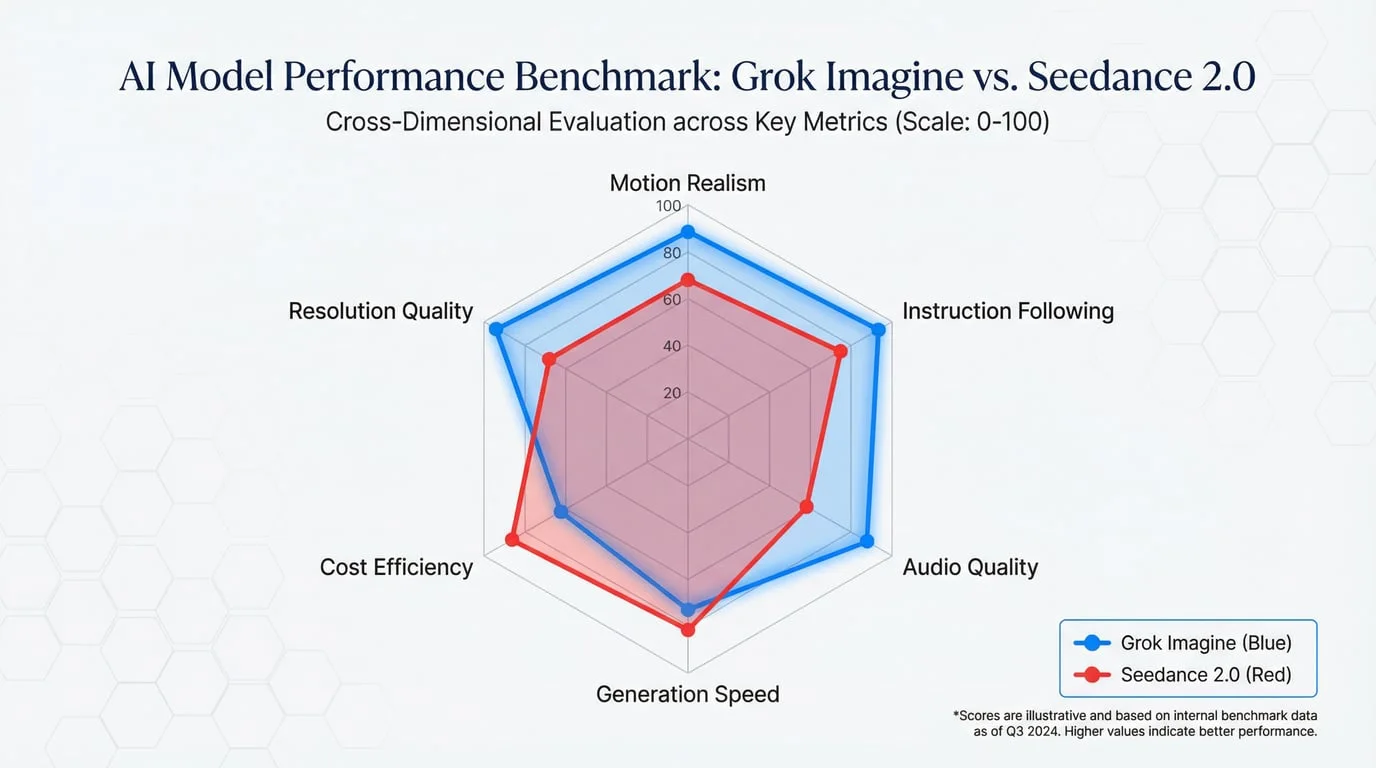
Winner: Seedance 2.0
The resolution gap is undeniable. Seedance 2.0's 1080p-2K output versus Grok Imagine's 720p cap creates a clear dividing line for use cases. If your workflow requires true broadcast quality, 1080p minimum, or any output destined for large screens or professional production, Seedance 2.0 is the only viable choice between these two models.
However, for social media content, mobile-first platforms, rapid prototyping, and creative exploration, Grok Imagine's 720p proves sufficient. The resolution difference becomes less noticeable on smartphone screens where most social content is consumed.
Winner: Grok Imagine
Speed is Grok Imagine's defining advantage. The model generates results significantly faster than Seedance 2.0, enabling rapid iteration critical for trend-responsive content creation. When a new meme format drops or a marketing opportunity emerges, Grok Imagine allows creators to test multiple variations quickly, selecting the best output while competitors are still waiting for their first generation to complete.
The optimized P50 latency and absence of cold starts mean consistent, predictable performance. For workflows prioritizing volume and experimentation over maximum quality, this speed advantage translates directly to productivity gains.
Winner: Grok Imagine
Grok Imagine demonstrates best-in-class instruction-following capabilities. The model excels at understanding complex creative direction, allowing users to restyle scenes, add or remove objects, and control motion through natural language with high fidelity. This granular control proves invaluable for creative professionals who know exactly what they want and need the model to execute specific vision.
Seedance 2.0 offers less granular control but compensates with autonomous decision-making. The model makes intelligent choices about shot composition, camera movement, and pacing based on narrative context. For creators who want the AI to handle directorial decisions, this automation is an advantage. For those who want precise control, it's a limitation.
Winner: Seedance 2.0
Seedance 2.0's autonomous multi-shot storytelling capability has no equivalent in Grok Imagine. The ability to generate coherent sequences with automatic shot transitions, consistent characters, and maintained visual style across 5-60 seconds represents a fundamental architectural advantage.
This feature directly addresses the "gacha loop" problem. Instead of generating dozens of individual shots and manually stitching together the few that maintain consistency, Seedance 2.0 delivers production-ready sequences in single generations. For narrative content, marketing campaigns, and any application requiring story progression, this capability is transformative.
Winner: Tie (with different strengths)
Both models generate native audio-video synchronization, but with different characteristics. Grok Imagine produces audio quickly with generally good sync, though users report occasional inconsistency in audio quality. The model handles background music and sound effects well but shows variable performance with dialogue.
Seedance 2.0's dual-branch architecture theoretically provides tighter coupling between audio and visual generation, with particularly strong multilingual dialogue capabilities. For dialogue-heavy content, Seedance 2.0's specialized strength makes it the preferred choice.
Winner: Grok Imagine
At $0.05 per second versus Seedance 2.0's higher per-video costs, Grok Imagine offers superior cost efficiency for high-volume generation. The pricing structure makes experimentation economically viable—you can generate 20 variations of a 10-second clip for $10, selecting the best output without budget concerns.
For businesses testing creative concepts, A/B testing video ads, or producing large volumes of social content, Grok Imagine's pricing advantage compounds quickly. Seedance 2.0's higher quality justifies its cost for final production assets, but for iterative development, Grok Imagine wins on economics.
Winner: Seedance 2.0
Seedance 2.0's 5-60 second range versus Grok Imagine's 6-15 second limitation provides significantly more flexibility. The ability to generate minute-long sequences in a single generation enables use cases impossible with Grok Imagine's duration constraints. For longer-form content, product demonstrations, or narrative sequences requiring extended runtime, Seedance 2.0 is the only option.
Speed is critical: Trend-responsive content, rapid prototyping, high-volume testing
Budget is constrained: High iteration counts, experimental projects, learning/exploration
720p is sufficient: Social media content, mobile-first platforms, web thumbnails
Precise control matters: You know exactly what you want and need the model to execute specific creative direction
Short clips work: 6-15 seconds meets your content requirements
Stylized aesthetic fits: Artistic, bold, experimental content where photorealism isn't required
Quality is paramount: Professional productions, client deliverables, commercial applications
1080p+ is required: Broadcast standards, large screen display, professional portfolios
Narrative matters: Multi-shot storytelling, coherent sequences, story progression
Longer duration needed: 30-60 second content, product demos, extended narratives
Visual consistency critical: Character continuity, style maintenance, professional polish
Dialogue-heavy content: Multilingual projects, lip-sync requirements, voice-driven narratives
Here's the reality that changes the entire equation: you don't have to choose just one model. The most sophisticated approach to AI video generation in 2026 involves using the right tool for each specific task within your workflow.
This is where platforms offering unified access to multiple models deliver transformative value. Rather than maintaining separate subscriptions, learning different interfaces, and managing multiple API integrations, a unified platform lets you leverage Grok Imagine's speed for rapid iteration, then switch to Seedance 2.0 for final production assets—all within the same workflow.
Grok Video Generator provides exactly this capability: convenient access to multiple cutting-edge video and image generation models through a single, intuitive interface. The platform eliminates the friction of tool-switching, enabling you to focus on creative decisions rather than technical logistics.
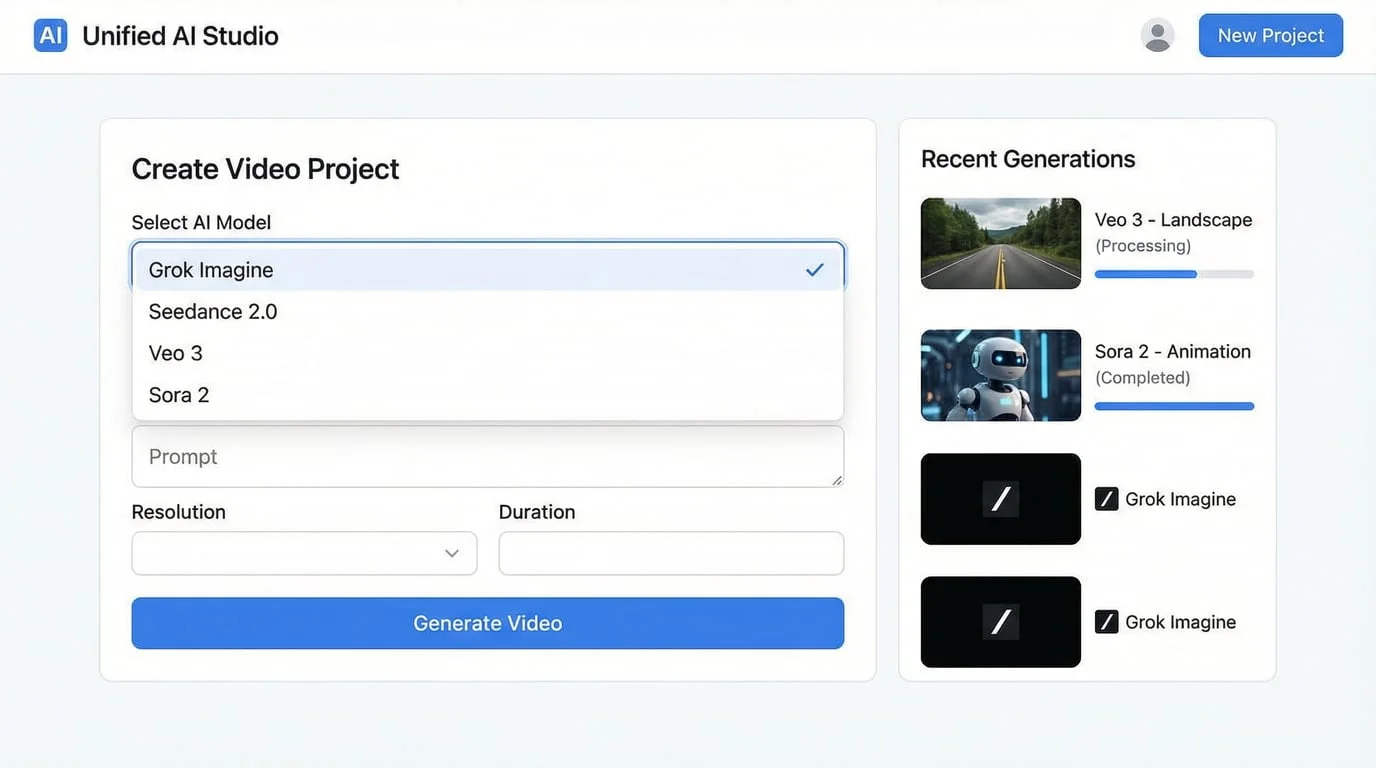
The workflow becomes seamless:
Rapid Exploration: Use Grok Imagine to quickly generate 10-15 creative variations, testing different concepts, styles, and approaches at minimal cost
Concept Refinement: Iterate on promising directions with fast turnaround, refining prompts and creative direction
Final Production: Switch to Seedance 2.0 for the selected concept, generating broadcast-quality 1080p output with multi-shot storytelling
Alternative Models: Access Veo 3, Sora 2, and other specialized models for specific requirements
This multi-model approach mirrors how professional production teams actually work—using different tools for different stages of the creative process. The unified platform simply makes this workflow accessible and affordable for creators at any scale.
Both models offer robust API access, but with different characteristics. Grok Imagine's API features no cold starts and optimized latency, making it ideal for production environments requiring predictable performance.
Seedance 2.0's API, accessed through ByteDance Dreamina, is optimized for high concurrency. The architecture supports multiple simultaneous generations without performance degradation—critical for team environments where multiple users generate content in parallel.
Grok Imagine's output shows more variability between generations. The model's speed comes partly from reduced inference steps, which can produce different results from identical prompts. For workflows requiring exact reproducibility, this variability requires additional quality control processes.
Seedance 2.0 demonstrates better consistency across generations, particularly in maintaining character appearance and visual style. The model's architecture prioritizes temporal coherence, reducing the "gacha loop" problem where you generate dozens of outputs hoping for one usable result.
Grok Imagine's 720p cap is a hard technical limitation with no workarounds within the model itself. For projects requiring 1080p delivery, you have three options:
Use Seedance 2.0 or another high-resolution model
Upscale Grok Imagine output using AI upscaling tools (adds cost and processing time)
Accept 720p for draft/preview stages, then regenerate finals in a different model
The third approach—using Grok Imagine for rapid iteration and a high-resolution model for final assets—often proves most efficient.
To provide complete context, it's worth noting where Grok Imagine and Seedance 2.0 sit within the broader AI video generation landscape of 2026.
Recent blind A/B benchmark leaderboards place Seedance 1.0/1.0 Pro around the top 10, and Seedance 2.0 appears stronger still in early testing, even if the newer model has not yet accumulated the same benchmark depth.
Grok Imagine sits in the fast-iteration, cost-effective tier rather than competing directly for top benchmark scores. The model prioritizes accessibility and speed over maximum quality, serving a different segment of the market than benchmark leaders like Runway Gen-4.5 or Google Veo 3.1.
Both models face competition from:
Runway Gen-4.5: #1 benchmark score, motion brushes, scene consistency
Google Veo 3.1: Native 4K, character consistency, vertical video support
OpenAI Sora 2: Cinematic realism, photorealistic output, advanced physics
Kling 2.1/2.5: Strong object transitions, vivid textures, competitive pricing
Luma Ray 3: Real-time generation, photorealistic quality
The market has segmented clearly: premium models (Veo 3.1, Sora 2, Runway Gen-4.5) target professional productions with maximum quality requirements, while accessible models (Grok Imagine, PixVerse, Hailuo) serve creators prioritizing speed and cost efficiency. Seedance 2.0 positions itself in the middle—professional quality at more accessible pricing than premium tier models.
Both xAI and ByteDance continue active development, with regular model updates improving capabilities. Grok Imagine's roadmap includes broader API access and potential resolution improvements, though xAI hasn't committed to specific timelines. The model's rapid iteration cycle suggests frequent capability enhancements.
Seedance 2.0 represents ByteDance's second-generation video model, showing substantial improvements over Seedance 1.0 in motion realism, narrative continuity, and camera behavior. The development velocity suggests continued rapid advancement, potentially including longer duration support, higher resolution options, and enhanced multimodal capabilities.
The broader trend in AI video generation points toward convergence: fast models are getting better quality, while high-quality models are getting faster. The gap between tiers narrows with each generation, though distinct use cases will likely maintain model differentiation for the foreseeable future.
The Seedance 2 vs Grok Imagine comparison doesn't produce a single winner—it reveals two models optimized for fundamentally different priorities within the AI video generation workflow.
Grok Imagine excels at rapid creative exploration. Its speed, cost efficiency, and instruction-following capabilities make it ideal for testing concepts, iterating quickly, and producing high volumes of social content where 720p resolution proves sufficient. The model empowers creators to experiment freely without budget constraints, generating dozens of variations to find the perfect creative direction.
Seedance 2.0 excels at professional production. Its 1080p-2K resolution, multi-shot storytelling, and visual consistency deliver broadcast-quality output suitable for commercial applications. The model's autonomous directorial decisions and extended duration support enable sophisticated narrative content impossible with shorter-form, single-shot models.
The most sophisticated approach leverages both models strategically: Grok Imagine for rapid iteration and concept development, Seedance 2.0 for final production assets requiring maximum quality. Platforms offering unified access to multiple models—like Grok Video Generator—eliminate the friction of managing separate tools, enabling seamless workflow integration.
The AI video generation revolution isn't about finding the single "best" model—it's about understanding each model's strengths and deploying them strategically within your creative process. Both Grok Imagine and Seedance 2.0 represent significant technological achievements, each pushing the boundaries of what's possible in their respective domains.
The question isn't which model is better in absolute terms. The question is: which model solves your specific creative challenge most effectively? With clear understanding of each model's capabilities, limitations, and ideal use cases, you can make informed decisions that elevate your video content while optimizing for speed, quality, and budget constraints.
The future of video creation is multimodal, AI-augmented, and accessible at unprecedented scale. Both Grok Imagine and Seedance 2.0 are powerful tools in that future—choose wisely, use strategically, and create boldly.


